A Book Recommender on AWS
2020-12-18
See the project repo on Github
Project context
For the last year, I've been a contractor for Equinox, a chain of fitness clubs based in NY and with locations around the world. One major ongoing initiative there is to build two apps: an iOS and Android-based general fitness application called Variis, and a SoulCycle (an Equinox brand) at-home stationary bike.
As a data scientist and engineer, one of my responsibilities has been to create batched content recommendations for users, matching each user with exercise classes they might like. Most of these recommendations have been made on relatively simple criteria, such as most popular classes in your favorite exercise category (running, strength, cycling, yoga, etc.). These recommendations are usually created with an Athena query kicked off by an AWS lambda.
At various points in the last year, we've looked to create more sophisticated recommendations, based on recommender system techniques such as collaborative filtering. On a very applied level, in a content recommendation context, collaborative filtering entails finding similarities between users, and then recommending pieces of content to each user based on what similar users liked or did.
However, because collaborative filtering is an intensive process and on our dataset could eventually require a greater run-time than the 15 minute limit for a lambda, we've considered using ECS to deploy a collaborative filtering-based recommendation engine. However, due to my inexperience with Docker and ECS, this has always been a task too time consuming to be worth taking time away from other tasks for what could be only a marginal lift in user experience.
With the opportunity to build something from scratch in Harvard Extension School's CSCI-E90 (Cloud Services and Infrastructure) final project, I no longer had this excuse, since I would be building a recommender system on my own time. For the project, I decided to build something similar to what we would want at work, using a different dataset: a compendium of 25M book reviews on GoodReads.
In order to keep things simple, I chose implicit collaborative filtering, making recommendations for what users might want to read based on what similar users read in the past.
Building locally
This project consisted of two main challenges: building the docker container, and posting it to ECR and running it on ECS.
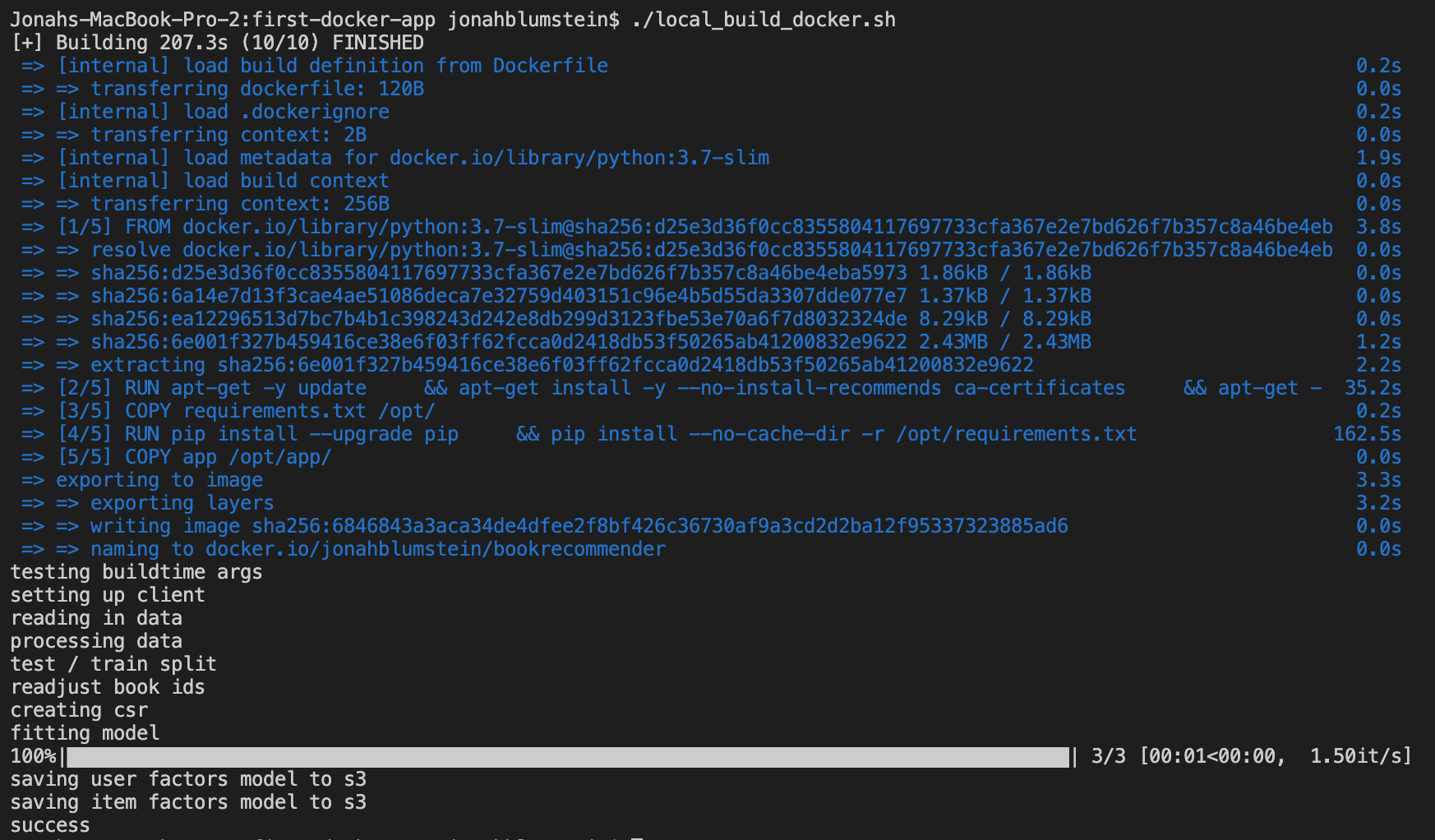
The former proved much easier than the latter. To build an image for reading in data from S3, running a model, and saving it to S3 as a pickle file, and then runs it in a docker container, all I needed to do was create a python file that did the work (app/container/app.py), a requirements file for the package imports I used (app/requirements.txt),a Dockerfile defining how to build the image (app/Dockerfile), a shell script to build the image locally and create a container to run the image in (local_build_docker.sh). I also created a config file to hold my environment variables (not submitted as it contains my AWS secrets, but see example_config for something similar) to hold environment variables used throughout the repo.
I'm going to hold off on going through my scripts for this part, as they are entirely non-cloud related. The result of running the build looks like this though:
Moving to the cloud
Working with docker on AWS was tougher, but I ultimately succeeded to posting my docker image to ECR and then running it in ECS using only CLI commands.
Posting to ECR
To post my docker image to ECR, I built a short shell script, with the following steps:
Set up, by reading in my environment variables and switching into my container folder (which contains the contents of my docker image):
>#!/bin/bash
source config
cd container
Next I logged in to AWS:
aws ecr get-login-password --region $aws_region docker login --username AWS --password-stdin repo_image
I then built my repo in ECR:
aws ecr create-repository --repository-name $repo_name
I next built my image with my argument values (ARGs in my Dockerfile) and tagged it:
docker build --build-arg aws_key=$AWSAccessKeyId --build-arg aws_secret=$AWSSecretKey -t $repo_name:$repo_tag .
docker tag $repo_name:$repo_tag $repo_image/$repo_name:$repo_tag
Finally, I pushed my image to ECR:
docker push $repo_image/$repo_name:$repo_tag
Here's my repo on ECR:

Running on ECS
The toughest part, by a good margin, was figuring out how to run my image, now in ECR, on ECS. In order to simplify things, I used Fargate, but I still needed a fairly lengthy shell script, a json file, and a Python script to build a task definition, to get it done from the CLI.
Let's dig in to it:
In my deploy_and_run_fargate.sh script, I had to take the following steps:
Read in environment variables:
source config
Create a name for the container I would use later on for my task:
dtnow="`date +%Y%m%d%H%M%S`"
container_name_dt=$container_name-$dtnow
Create an IAM role to execute my task:
aws iam --region $aws_region create-role --role-name $role_name --assume-role-policy-document file://task-execution-assume-role.json
aws iam --region $aws_region attach-role-policy --role-name $role_name --policy-arn arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy
Fill out my task template, using a python script:
python3 update_task_definition.py $container_name_dt
The python script reads in my environment variables, gives them names during the script runtime, fills out the below dictionary, and saves it to a json file named updated_task_definition.json (not included here because it includes secrets).
template = {
"executionRoleArn": f"arn:aws:iam::{aws_account_id}:role/{role_name}",
"containerDefinitions": [{
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": log_group_name,
"awslogs-region": aws_region,
"awslogs-stream-prefix": "ecs"
}
},
"image": f"{repo_image}/{repo_name}:{repo_tag}",
"name": container_name
}],
"memory": "8192",
"taskRoleArn": f"arn:aws:iam::{aws_account_id}:role/{role_name}",
"family": task_definition_name,
"requiresCompatibilities": ["FARGATE"],
"networkMode": "awsvpc",
"cpu": "2048"
}
Create a cluster on ECS, putting it in Fargate mode so I don't have to deal with servers:
aws ecs create-cluster --cluster-name cluster_name --capacity-providers FARGATE
Here's what it the cluster looks like in the AWS console:

Create a log group on Cloudwatch:
aws logs create-log-group --log-group-name $log_group_name
Register my task definition, using the json file that I created in my Python script:
aws ecs register-task-definition --cli-input-json file://updated_task_definition.json
In the AWS console, it looks like this:

And run my task in my cluster, specifying that I was using Fargate and specifying the subnets and security groups for my VPC:
aws ecs run-task --launch-type FARGATE --task-definition $task_definition_name --cluster arn:aws:ecs:$aws_region:$aws_account_id:cluster/$cluster_name --network-configuration "awsvpcConfiguration={subnets=[$subnet1,$subnet2],securityGroups=[$security_group],assignPublicIp=ENABLED}"
A lot of work to run my simple docker image on AWS, especially considering I did it in a "serverless" way! However, it was gratifying to see my task run successfully on command and to see a new Pickle file populate in S3.
Logs for the run:

My output folder for the model in S3 after the run:

Tags: data science, python, aws